La prioritizzazione è l’arte di rispondere alle domande "da dove comincio?" e "con cosa proseguo?"
In questo articolo analizziamo come raffrontare teoria e pratica per risolvere nel modo più efficace una problematica di sicurezza che affligge aziende di ogni dimensione, ordine e grado: il rimedio della superficie vulnerabile.
Questo problema si presenta normalmente con l'evoluzione della maturità nella gestione del ciclo di vita delle vulnerabilità presenti nel proprio panorama IT. Quando un'azienda decide di strutturare un programma per stimare, analizzare e comprendere la propria superficie vulnerabile, il punto di partenza è utilizzare sistemi più o meno commerciali per sondare i propri sistemi interni ed esterni, infrastrutturali ed applicativi, al fine di capirne il grado di resilienza rispetto alle vulnerabilità note.
Questo processo di solito parte con scansioni a periodicità variabile, che generano report sulle vulnerabilità identificate. Lungi da essere un punto di arrivo, questo inizio normalmente evidenzia una quantità di problematiche enorme, il cui potenziale rimedio è assolutamente fuori portata rispetto alle capacità dell'azienda.
Da qui l'esigenza di gestione del ciclo di vita di tale superficie vulnerabile, esaminando diversi elementi con il fine di capire come utilizzare al meglio le capacità di mitigazione minimizzando il rischio residuo.
Fino a utilizzare contesti espansi, come ad esempio informazioni di compromissibilità o più in generale di Intelligence della minaccia cyber. Ecco definita l'evoluzione da Vulnerability Assessment, a Vulnerability Management ed infine a Threat & Vulnerability Management.
Vediamo quindi in teoria alcuni metodi per determinare la corretta priorità di azione.
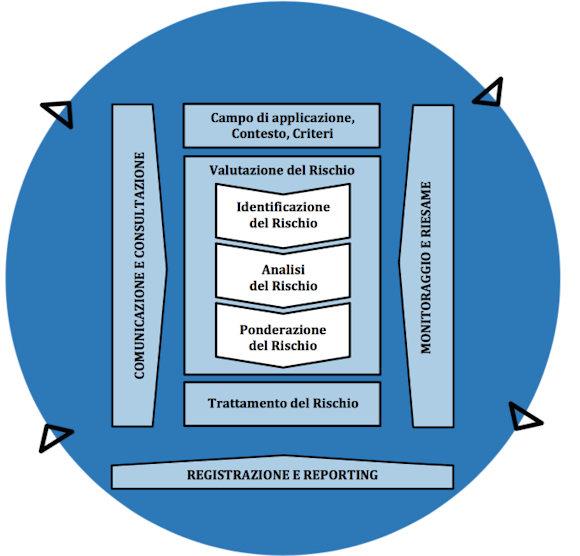
Prima di addentrarci nella teoria è bene fare una premessa: calcolare la priorità fa parte di un piano più grande che è quello della valutazione del rischio. A tal proposito si rimanda alla norma ISO 31010:2019 [1] e ai documenti del NIST SP-800-37 [2] e SP-800-30 [3], in particolare agli elementi che compongono la valutazione: identificazione, analisi e ponderazione del rischio come illustrato di seguito.
Un punto chiave per avere un piano di rimedio efficace è quello di assegnare opportunamente le priorità. Introduciamo quindi l’approccio sull’analisi del rischio e il metodo utilizzato. Il NIST divide l’approccio in: orientato alle minacce, orientato agli impatti e orientato alle vulnerabilità.
Per brevità viene preso come modello di rischio quello orientato alla minaccia, in cui prioritizzare il rischio significa valutare le minacce e – dopo aver calcolato una matrice di rischio – ricavare un valore numerico: più alto è il valore, più alto sarà il rischio.
Per quanto riguarda i metodi di valutazione del rischio si dividono principalmente in metodi qualitativi, quantitativi e semi-quantitativi.
La letteratura ci insegna che nel metodo qualitativo per poter prioritizzare il rischio ho bisogno di calcolare per ogni minaccia un punteggio, il cosiddetto Risk Score, dato da Probabilità x Impatto secondo la formula R = P x I.
La probabilità indica la possibilità che un evento inatteso e in grado di causare danno – in questo caso la minaccia – si verifichi; l’impatto indica il danno potenzialmente provocato dalla minaccia.
Utilizzando una matrice di rischio 5x5 si assegna a ogni minaccia una probabilità e un impatto, con differenti livelli qualitativi come mostrato nella figura sottostante.

Il vantaggio di tale approccio è nel classificare i rischi, concentrandosi su quelli a più alta priorità.
Per contro, l’analisi qualitativa è soggettiva e si basa sulla percezione che gli stakeholder hanno nei confronti delle minacce analizzate, unite alle loro esperienze e competenze.
Il metodo quantitativo ha un approccio più strutturato.
Potendo contare su tempo e risorse da dedicare, abbiamo la possibilità di avere dati statistici – ad es. quante volte un evento si è verificato in un anno – oltre ad un’analisi di impatto accurata – ad es. il servizio “X” se inattivo fa perdere 1000 euro/ora.
Diventa quindi possibile “tradurre” il rischio in numeri significativi a supporto di decisioni strategiche.
Il metodo quantitativo utilizza i parametri EF (Exposure Factor), SLE (Single Loss Expectancy), ARO (Annualized Rate of Occurrence) e ALE (Annualized Loss Expectancy).
La perdita prevista per il singolo asset è uguale a:
SLE = valore asset x EF
SLE misura quanto una minaccia influisce su un determinato asset, come un server, un framework o anche un servizio composto di software e hardware.
ARO misura invece quale è la frequenza di tale minaccia durante l’arco temporale di un anno. L’aspettativa di perdita economica per un dato asset nel corso dell’anno è data da:
ALE = SLE x ARO
Facendo un esempio numerico, supponiamo che un’impresa abbia un servizio e-commerce che fattura 1 milione di euro all’anno; si prende quindi in considerazione il servizio di vendita composto dall’insieme di hardware, software e persone che lavorano.
Ipotizziamo che un attacco DDoS, che blocchi le vendite e l'attività delle persone operative, abbia un fattore di esposizione del 5%.
Infine supponiamo che tale tipo di attacco sia stato portato a segno 6 volte negli ultimi 3 anni cioè abbia una ARO=6/3 => ARO=2.
SLE = 1.000.000€ x 0.05 = 50.000€
ALE = 50.000€ x 2 = 100.000€
Seguendo il modello di rischio descritto, l'azienda perde in media 100.000€ per anno.
Volendo semplificare l’esempio, un piano di remediation potrebbe essere quello di installare un next generation Firewall con IDS/IPS per bloccare questi attacchi DDoS per un costo pari a 50.000€ + 5.000€/anno di manutenzione.
Attraverso il metodo semi-quantitativo, le valutazioni vengono fatte secondo metodi qualitativi per poter prioritizzare subito il rischio e attivare un piano d’azione, per poi rielaborare i dati e trasformare i termini qualitativi in numeri per fornire una stima economica più accurata.
Dopo questa prima parte teorica, analizzando la pratica nella gestione di una superficie vulnerabile in ambienti IT complessi vediamo che il livello di difficoltà cresce: per mettere in priorità le azioni di rimedio è necessario agire combinando alcuni dei metodi illustrati, in modo da raggiungere una percezione del rischio e della minaccia più descrittiva che analitica, mappata sulla propria superficie digitale.
Come visto il rischio è complesso da calcolare, specialmente il rischio cyber.
Molto diverso da altri tipi di rischio (finanziario, imprenditoriale), si presenta multi-sfaccettato e basato su evidenze certe e percezioni di intelligence. Diventa importante non fidarsi soltanto di una rappresentazione numerica di severità, criticità, in favore di una percezione descrittiva del rischio.
Devo in sostanza poter descrivere cosa mi preoccupa, per contare su un sistema che converta queste mie percezioni in fattori di prioritizzazione.
Esempi di descrizione:
- Perimetro, cioè la capacità di abbinare il sistema su cui viene scoperta la vulnerabilità al perimetro di cui fa parte, per aumentare (o diminuire) la criticità oggettiva della risorsa.
- Età delle vulnerabilità, considerando sia quando sono apparse in pubblico che quando sono state rilevate nel proprio ambiente digitale.
- Impatto sul business: ad esempio considerare tutte le vulnerabilità che se compromesse possono agevolare un attacco DDoS, oppure un’infezione che si propaga tramite worm, oppure ancora un focolaio di ransomware.
- Probabilità che la minaccia si tramuti in attacco: ad esempio se una vulnerabilità è già armata con un exploit, magari già parte di Exploit Kit facili da reperire (anche a noleggio) per un attaccante motivato; è infatti certamente più alta la probabilità che questa venga sfruttata per un attacco, rispetto ad una vulnerabilità sconosciuta o per cui la tecnica di compromissione deve ancora essere sviluppata.
- Superficie di attacco propria. Sun Tzu diceva “conosci te stesso e conosci il tuo nemico e sopravviverai a cento battaglie”. Conoscere il proprio panorama digitale aiuta a mettere in priorità il rimedio in base al contesto di rete su cui si deve operare.
- Ad esempio, concentrandosi sul rimedio di vulnerabilità presenti solo su kernel o servizi in esecuzione. Oppure primariamente su sistemi esposti ad internet.
Un esempio di come una piattaforma tecnologica supporti questa descrizione percettiva del rischio è riportato qui di seguito, prendendo spunto dalla soluzione Qualys:
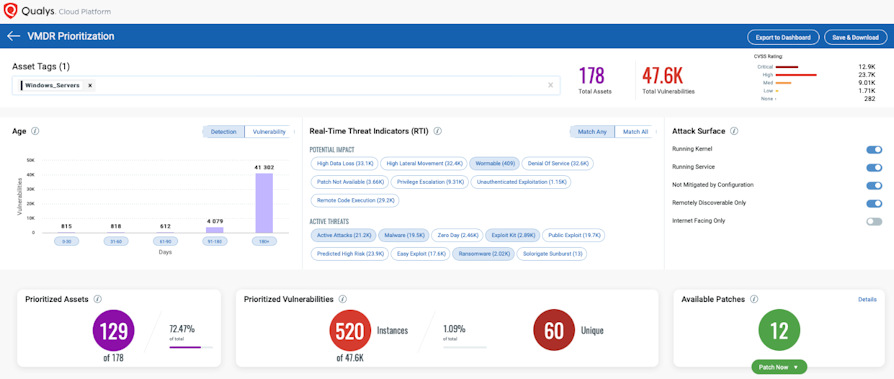
Una volta descritta la percezione della minaccia è importante avere un ulteriore contesto, in merito alle patch: sia quelle disponibili che quelle già installate sui sistemi, per effettuare su queste ultime un controllo di obsolescenza.
È anche importante analizzare le vulnerabilità derivanti da errate configurazioni – soprattutto in ambienti tipo cloud dove la responsabilità è condivisa: se istanzio uno storage su AWS o Azure e mi dimentico di restringere la lista degli IP che vi può accedere rischio un data leakage gravissimo; se dimentico di attivare l’autenticazione multifattore su un’istanza, le conseguenze potrebbero essere anche peggiori.
Spesso l’attività di rimedio (patching, modifica configurazione, implementazione controlli compensativi) viene eseguita da team aziendali che non sono gli stessi a cui è demandato il rilevamento e la classificazione delle vulnerabilità... quindi serve un collante interdipartimentale che agevoli integrazione e automazione per evitare conflitti e inefficienze operative. Questo può tradursi nello sfruttamento di interfacce di programmazione applicative (API) che possono essere attivate per trasformare le informazioni di ogni singola piattaforma/applicazione in flussi informativi cifrati e sicuri, che diventino fattori abilitanti per i flussi operativi interdipartimentali.
Ultimo tema il tracciamento dello status quo, altrimenti chiamato osservabilità.
Questo si traduce nello studio di forme di aggregazione di dati grezzi in informazioni più semplici da comprendere; può avvenire con una rappresentazione dinamica – come le dashboard – oppure statica – come report in PDF o altri formati – che aiutino a tenere traccia nel tempo dei progressi, delle anomalie rilevate e di inefficienze nel processo.
Ad esempio, aggregare le vulnerabilità rilevate negli ultimi 30 giorni, da 30 a 60, da 60 a 90.
Quindi per ogni categoria mappare l'esistenza di una patch per rimediare, evidenziando per quelle vulnerabilità la disponibilità di exploit.
Infine rendere questa informazione dinamica, costantemente aggiornata in modo da fornire a ogni parte interessata l'immagine dello status quo e dell'efficienza del processo di rimedio.
Rimediare una superficie vulnerabile anche molto ampia ed articolata non è certamente semplice; tuttavia l'organizzazione di un ciclo di vita monitorato e prioritizzato in modo olistico ed efficace permette di confinare il rischio residuo ad un livello accettabile, evitando una pericolosa trasformazione in superficie di attacco.
Riferimenti:
[1] https://www.iso.org/standard/72140.html - IEC 31010:2019 Risk management — Risk assessment techniques
[2] https://csrc.nist.gov/publications/detail/sp/800-37/rev-2/final - Risk Management Framework for Information Systems and Organizations: A System Life Cycle Approach for Security and Privacy
[3] https://csrc.nist.gov/publications/detail/sp/800-30/rev-1/final - Guide for Conducting Risk Assessments